




At Nida Ai, we have developed an advanced solution for extracting and analyzing data from complex PDF documents, enabling enterprises to unlock valuable insights from their vast repositories of information.
Enterprises often possess massive volumes of PDF documents containing critical data in various formats, including text, tables, charts, and images. Extracting meaningful information from these diverse and unstructured data types is challenging, leading to underutilization of valuable insights and inefficiencies in data processing.
Traditional PDF data extraction tools primarily focus on text extraction and often struggle with accurately interpreting complex elements like tables, charts, and images. These limitations result in incomplete data retrieval and necessitate extensive manual intervention to process and analyze the extracted information.
At Nida Ai, we have developed a powerful Multimodal PDF Data Extraction system that enables enterprises to unlock hidden insights from complex PDF documents. Unlike traditional extraction tools that primarily focus on text, our system leverages AI-powered multimodal processing to accurately extract and interpret text, tables, charts, and images from documents. By combining Natural Language Processing (NLP), Object Detection, and Computer Vision, our solution ensures that no valuable data is overlooked, making it a robust tool for data-driven decision-making.
Our automated extraction pipeline processes PDFs using specialized AI models designed to detect tables, deconstruct charts, and analyze embedded images. The extracted data is then structured into a unified format, ensuring seamless integration with enterprise applications. This eliminates the need for manual data entry, significantly reducing errors and enhancing operational efficiency. Additionally, our solution supports multimodal data integration, combining information from different elements of a document to provide a holistic understanding of its content.
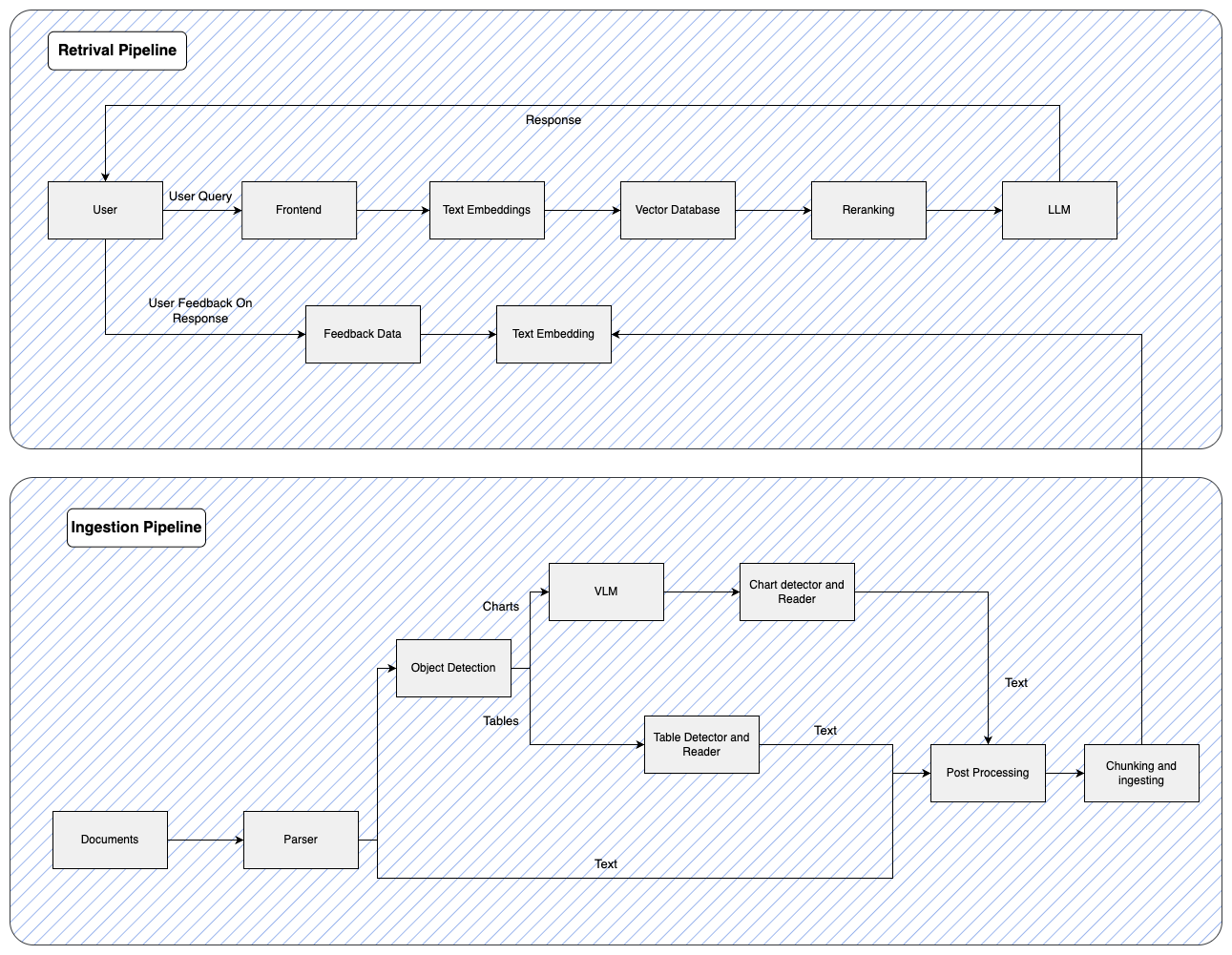
Utilizes natural language processing (NLP) models to extract and interpret textual data from PDFs.
Table Detection and Extraction:Employs object detection models to identify tables within document images and extract their content accurately.
Chart and Image Analysis:Applies specialized models to detect and deconstruct charts and images, converting visual information into structured data.
Multimodal Data Integration:Combines extracted data from various modalities to provide a comprehensive and coherent representation of the document's information.
Accurately retrieves information from diverse data types within PDFs, ensuring no valuable data is overlooked.
Reduced Manual Effort:Automates the extraction process, minimizing the need for manual data entry and reducing the potential for human error.
Enhanced Data Utilization:Transforms unstructured data into structured formats, facilitating easier analysis and decision-making.
Scalability:Capable of processing large volumes of documents efficiently, making it suitable for enterprise-scale applications.